Introduction:
As I mentioned ealier, I want to crawl some valuable data from Mods For Melon Playground. This guide provides a step-by-step walkthrough. Let’s get stared!
Setting Up the Project
Begin by creating a new Kotlin project and adding Selenium WebDriver as a dependency in your build file. If you missed the initial setup, check out the details in the previous article.
Scraping Data from Melmod
Get List of All Article Links
Our first objective is to crawl a list of article links from the Melmod website. To achieve this, create a new class, MelModGetLinks.kt, within the test module.
Inside this class, initialize the WebDriver and CSVWriter. The detailed code for this can be found in the provided snippet:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
class MelModGetLinks {
private lateinit var driver: WebDriver
private lateinit var csvWriter: CSVWriter
@BeforeEach
fun setup() {
// Create ChromeOptions
val chromeOptions = ChromeOptions()
// Disable images loading
val prefs: MutableMap<String, Any> = HashMap()
prefs["profile.managed_default_content_settings.images"] = 2
chromeOptions.setExperimentalOption("prefs", prefs)
// It doesn't render the UI if running the browser in headless mode
chromeOptions.addArguments("--headless")
// Initialize the WebDriver
driver = ChromeDriver(chromeOptions)
// Navigate to the website
driver.get("https://melmod.com/mods/")
// The output CSV file
csvWriter = CSVWriter(FileWriter("src/test/resources/melmod-link.csv"))
}
@AfterEach
fun tearDown() {
driver.quit()
csvWriter.close()
}
}
|
We have everything to do. Get back to the MelMod website. As we can see, every article has post inside class attribute:
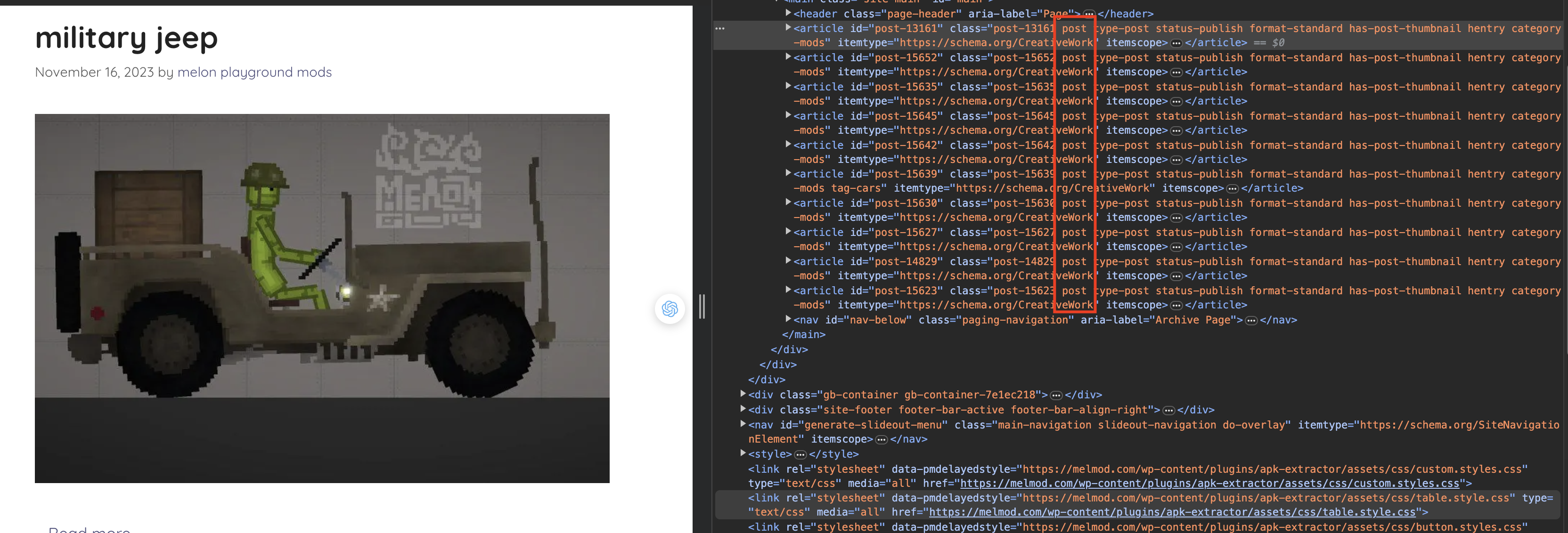
So we can get all article names and detail links by get all elements have post in className. We can achieve it through the following code snippet:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
@Test
fun `Get list links from pages - success`() {
// Add header to csv file
addHeaderForCSV()
// Get link from pages
val firstPage = 1
val lastPage = 2
val pages = (firstPage..lastPage).toList()
for (page in pages) {
// Navigate to the website in specific page
driver.get("https://melmod.com/mods/page/$page/")
// Get all articles available with class `post`
val articles = driver.findElements(By.className("post"))
Assertions.assertEquals(articles.size, 10)
// Get link of each article
articles.forEachIndexed { index, article ->
val h2 = article.findElement(By.className("entry-title"))
val a = h2.findElement(By.tagName("a"))
val link = a.getAttribute("href")
insertToCSV(10*(page-1)+(index+1), link, h2.text)
}
}
}
private fun addHeaderForCSV() {
val header = arrayOf("Index", "Link", "Name")
csvWriter.writeNext(header)
}
private fun insertToCSV(index: Int, link: String, name: String) {
val row = arrayOf(index.toString(), link, name)
csvWriter.writeNext(row)
println("CSV: $index, $link, $name")
}
|
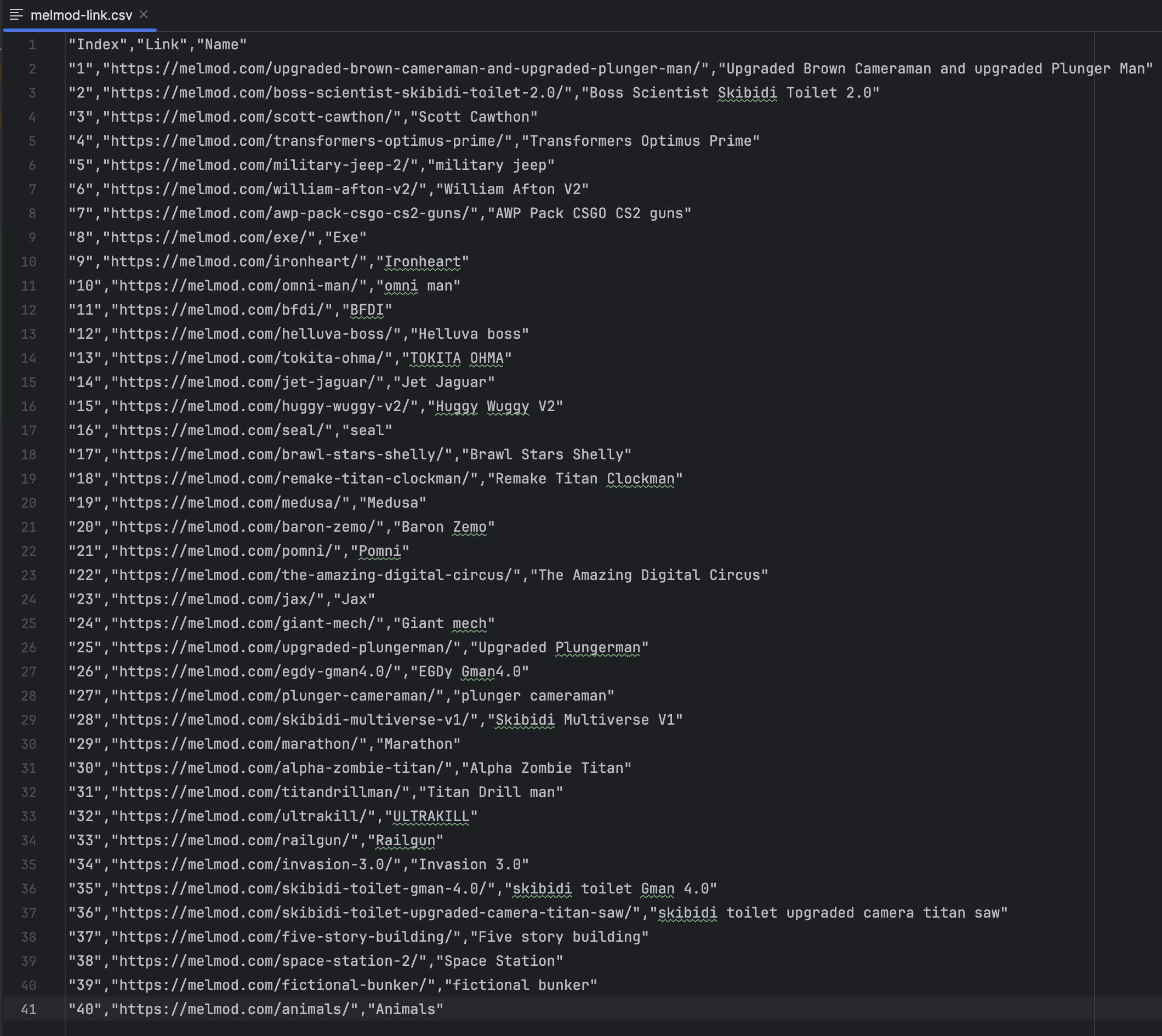
This code navigates to the Melmod website and extracts all article name and detail links using a className. Result will appear in src/test/resources:
Extract Valuable Data from Each Article
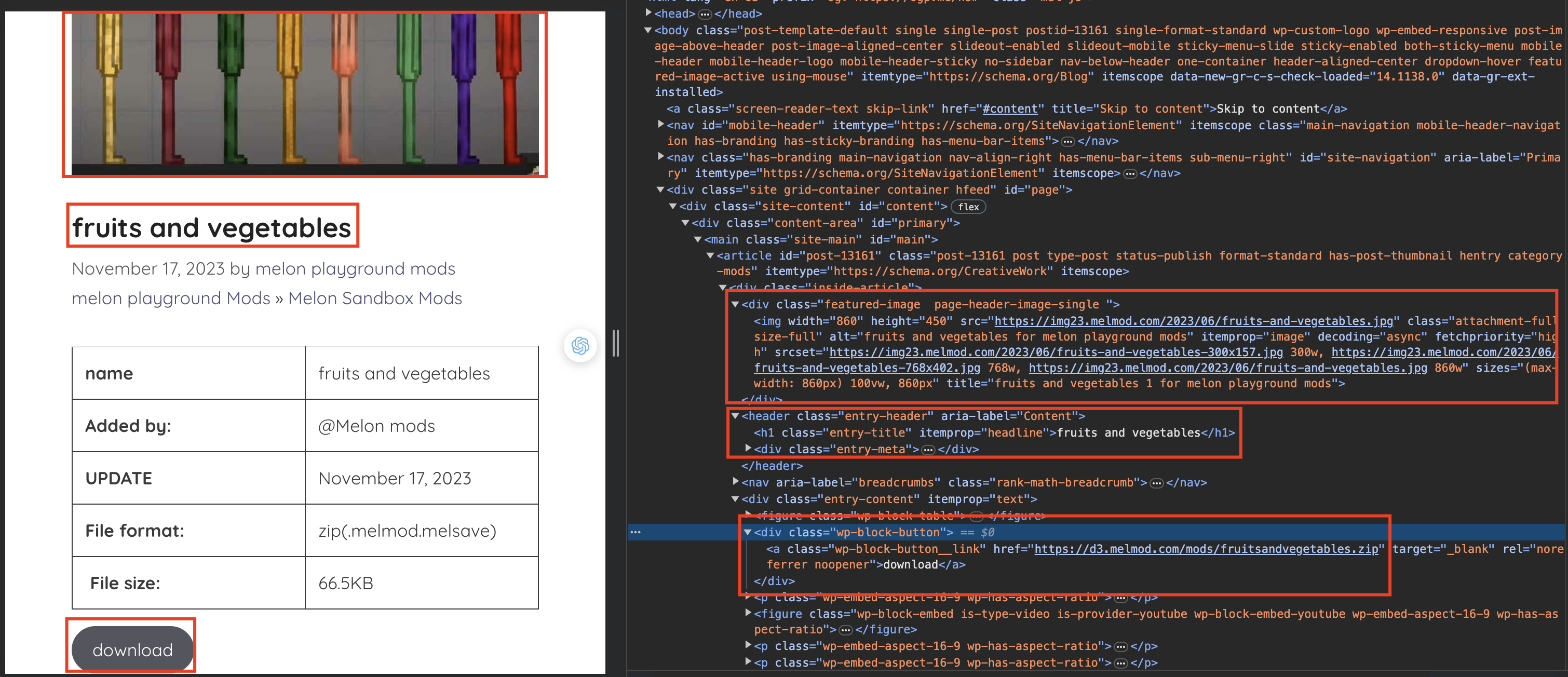
Once we have the article links stored in src/test/resources/melmod-link.csv, the next step is to delve into each article and the desired data—image, name, and mod file link:
- Image: by finding the
div element has featured-image in class attribute.
- Name: by finding the
h1 tag has entry-title in class attribute. But I have a name in the first step. So I don’t need to get the name again in this step
- Mod File Link: by finding the button has
wp-block-button in class attribute.
For more information, you can see the image below:
The full source code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
class MelModGetFiles {
private lateinit var driver: WebDriver
private lateinit var csvReader: CSVReader
private lateinit var csvWriter: CSVWriter
@BeforeEach
fun setup() {
// Create ChromeOptions
val chromeOptions = ChromeOptions()
// Disable images loading
val prefs: MutableMap<String, Any> = HashMap()
prefs["profile.managed_default_content_settings.images"] = 2
chromeOptions.setExperimentalOption("prefs", prefs)
// It doesn't render the UI if running the browser in headless mode
chromeOptions.addArguments("--headless")
// Initialize the WebDriver
driver = ChromeDriver(chromeOptions)
// Initialize the CSVReader
csvReader = CSVReader(FileReader("src/test/resources/melmod-link.csv"))
// Initialize the CSVWriter
csvWriter = CSVWriter(FileWriter("src/test/resources/melmod-fileMods.csv"))
}
@AfterEach
fun tearDown() {
driver.quit()
csvReader.close()
csvWriter.close()
}
@Test
fun `Get all file links from melmod-link csv - success`() {
// Write header for output
addHeader()
// Read header of input file. Don't need to care the header
csvReader.readNext()
// Start reading the input data
var nextRecord: Array<String>?
while (csvReader.readNext().also { nextRecord = it } != null) {
// Process data for each row
val index = nextRecord!![0]
val link = nextRecord!![1]
val name = nextRecord!![2]
findFileLinkAndAddToCSV(index, link, name)
}
}
private fun addHeader() {
val header = arrayOf("Index", "Name", "Image", "File")
csvWriter.writeNext(header)
}
private fun findFileLinkAndAddToCSV(
index: String,
link: String,
name: String
) {
// Navigate to mod detail
driver.get(link)
// Get the mod image
val imageDiv = driver.findElement(By.className("featured-image"))
val imageTag = imageDiv.findElement(By.tagName("img"))
val imageLink = imageTag.getAttribute("src")
// Get the mod file link
val downloadButton = driver.findElement(By.className("wp-block-button"))
assertEquals(downloadButton.text, "download")
val a = downloadButton.findElement(By.tagName("a"))
val fileLink = a.getAttribute("href")
insertToCSV(index, name, imageLink, fileLink)
}
private fun insertToCSV(
index: String,
name: String,
image: String,
file: String
) {
val row = arrayOf(index, name, image, file)
csvWriter.writeNext(row)
println("CSV: $index, $name, $image, $file")
}
}
|
This code iterates through each article link, navigates to the corresponding page, and extracts the image and file link.
Result
After completing these 2 steps, you’ll have successfully scraped all the data you need. The resulting information will be stored in src/test/resources/melmod-fileMods.csv, as illustrated in the provided image:

Drawbacks
While web scraping is a powerful tool, it comes with certain drawbacks that should be considered:
- Performance: Currently, the extraction of data from each article takes approximately 2 minutes, which might be deemed sluggish. I will find a way to improve it later.
Conclusion
Armed with the ability to fetch article links and extract valuable data, you are now equipped to scrape essential information from Mods For Melon Playground.
Remember to check the website’s terms of service and policies before scraping to ensure compliance. Feel free to customize the code according to your specific scraping needs. Happy coding!
